



Stable Diffusion webUI 与ComfyUI使用中遇到问题与解决办法分享。大家有更好的解决方法也可以分享到这里,共同维护Stable Diffusion流畅的使用环境。
所有问题均出自以下两门课程中的同学提问。


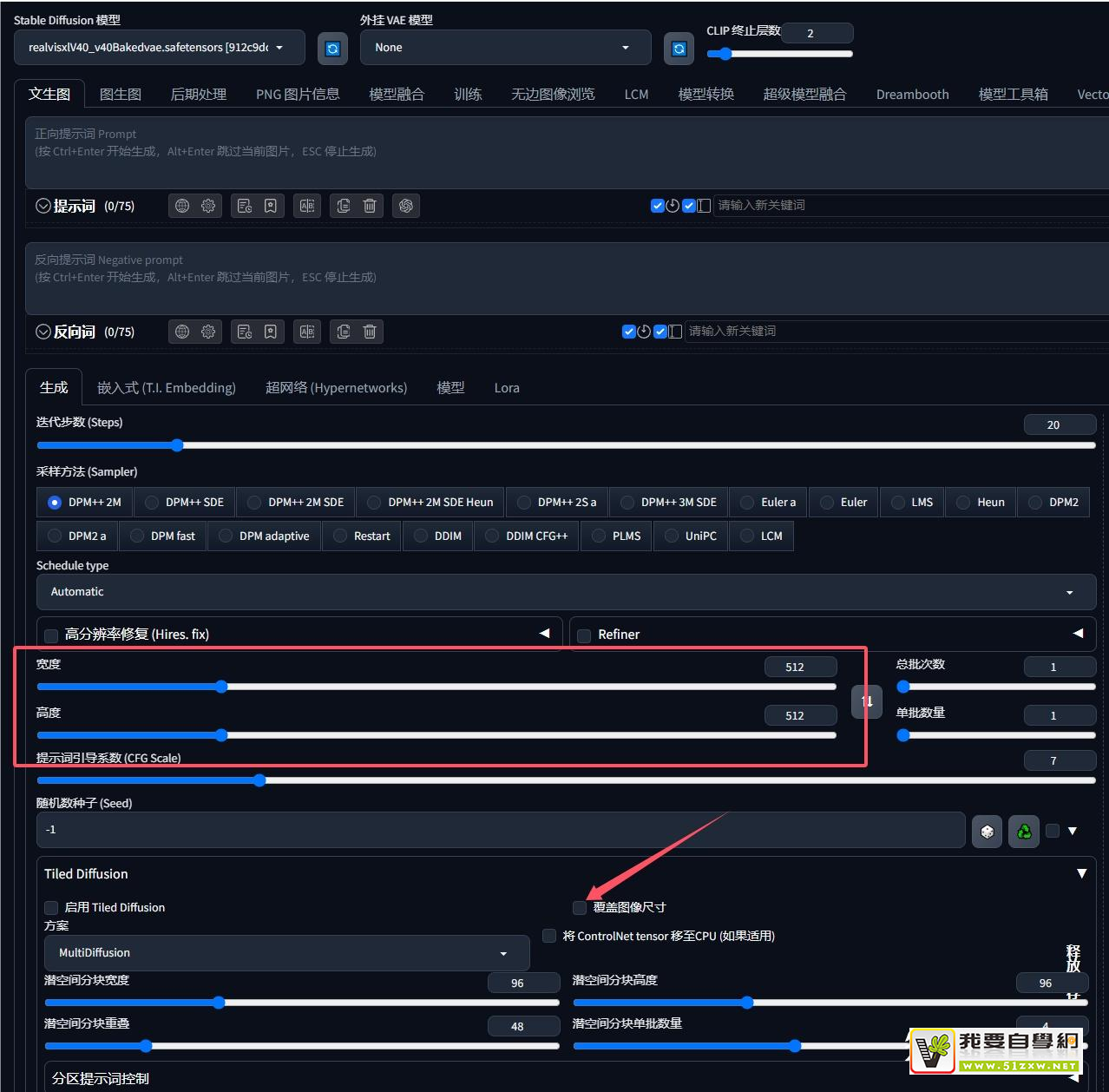
1:stable diffusion没有图像宽度和高度的调节?
UI:Stable Diffusion WebUI
原问题:我的stable diffusion 点开后为什么没有出现图像宽度和高度的调节呢?其他的都和老师一样。
问题所在章节:2-22 Tiled Diffusion与Tiled VAE插件讲解(一)
解决办法:
stable diffusion 在文生图和图生图选项卡中的设置是不一样的,在图生图中才有图像尺寸设置与放大倍数设置。不过版本更新之后,没有了图像尺寸设置。现在“保持输入图像大小”对钩取消之后,不再出现尺寸宽高设置。而是直接调用图生图的宽高设置。
2:Stable Diffusion局域网共享ip地址后的端口号是如何确认的?
UI:Stable Diffusion WebUI
原问题:老师,ip地址后的端口号是如何确认的?
问题所在章节:5-14 局域网共享、手机及外网使用讲解
解决办法:
Stable Diffusion WebUI 的默认端口号是7860,如果需要自己设置端口号按以下步骤设置。
打开启动器——“高级选项”——“监听设置”——“监听端口”,在这里修改端口号就可以。
至于端口号怎么确认,只要是同一类型的端口号且与其他程序端口号不冲突的都可以。
3:Stable Diffusion出现多余四肢怎么解决?
UI:Stable Diffusion WebUI
原问题:老师为啥,图像会有多余的衣服、物品、四肢。用啥提示词可以完美避免?
问题所在章节:2-27 Controlnet操作界面讲解二
解决办法:
在SD1.5大模型使用的时候可以在反向提示词中添加如下类似的提示:worst quality , bad proportions, twins, missing body, fused body, extra head, poorly drawn face, bad eyes, deformed eye , unclear eyes, cross-eyed , long neck, malformed limbs, extra limbs, extra arms, missing arms , bad tongue, strange fingers , mutated hands, missing hands, poorly drawn hands, extra hands, fused hands, connected hand , bad hands, wrong fingers , missing fingers, extra fingers, 4 fingers, 3 fingers, deformed hands, extra legs, bad legs, many legs, more than two legs, bad feet, wrong feet, extra feets,
提示词影响效果有限。新出的SDXL 与SD3.0在出图效果上有了很大的提高。比较有效的办法是更换更好的大模型、使用LoRA、Embeddind等。
此处出现畸形是因为大模型对提示词的理解与Controlnet的姿势指导不一致,各自发挥作用导致。所以不建议用复杂的动作去指导模型生成图。
4:layerdiffuse插件安装后不显示?
UI:Stable Diffusion WebUI
原问题:老师,您好!我安装了layerdiffuse,但是用户界面看不到layerdiffuse,这是咋回事?
问题所在章节:6-6 电商产品换背景
解决办法:
- 首先安装完毕后在启动器的“版本管理 ”——“扩展”中找一下,看是否已经安装。如果这里没有,说明安装没有成功,需要重新安装。可以通过多种方式安装,在扩展中直接安装不成功就用网址进行安装。
- 确保已经安装,重启webUI查看是否显示。如果任然不显示,可能是版本冲突造成。在“版本管理”——“扩展”找到layerdiffuse进行版本切换,切换为旧的版本,然后再次重启查看是否显示。多切换几个版本进行查看。
5:Canny线稿上色无法正常上色?
UI:Stable Diffusion WebUI
原问题:怎么我用CANNY来给线稿上色都是乱七八糟的呢
问题所在章节:2-30 Controlnet canny边缘检测模型讲解二
解决办法:
- Canny线稿上色要注意几点:
- 1:如果是白底黑线的稿件需要用预处理器进行反转黑白。
- 2:如果是对照片提取线稿后上色,要调整阈值控制线稿合理的细节。
- 3:需要书写提示词引导上色,否色无法正确上色。
6:Stable Diffusion WebUI forge加载扩展提示错误URLError: <urlopen error [Errno 11001] getaddrinfo failed>?
UI:Stable Diffusion WebUI forge
原问题:老师,加载扩展后一直这样,URLError: <urlopen error [Errno 11001] getaddrinfo failed>,请问怎么解决?
问题所在章节:5-16 Stable diffusion webui forge版本讲解
解决办法:
- 网络连接失败导致。WebUI forge版本安装的是原版,所有涉及到网络连接的都需要开启科学上网,否则无法加载。需要开启科学上网。
7:错误提示:Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>>
UI:Stable Diffusion WebUI
原问题:Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> 老师刚安装好的,第二次再打开就出现这个
问题所在章节:1-7 Stable Diffusion下载与安装之整合包安装法
解决办法:
- 重新安装“启动器运行依赖”。如果你是自己安装的Python,安装的时候记得勾选"Add Python 3.10 to PATH"
8:Stable Diffusion WebUI forge 界面没有SVD和Z123了?
UI:Stable Diffusion WebUI forge
原问题:请问老师,为什么加载后,没有SVD和Z123了?
问题所在章节:
解决办法:
- 目前作者正在进行一周的大修订,如果更新到最新版本的话会进入测试版本,测试版目前没有没有SVD和Z123。可以点此链接下载之前的版本https://github.com/lllyasviel/stable-diffusion-webui-forge/discussions/849或者等作者大改之后再更新到最新。
9:Stable Diffusion小内存图片任然爆显存。
UI:Stable Diffusion WebUI
原问题:老师,我用自己手机拍的照片,去做后期处理,出现显卡不够用,我的是4060显卡为什么跑不动呢,网上下载的图片都没问题,而且我ps压缩到100kb还是跑不动?
问题所在章节:1-12 Stable Diffusion启动器页面介绍与设置
解决办法:
- 首先显存的占用和图片本身的内存大小没有直接的关系,和图片像素的多少有关。也就是和图片的像素尺寸有关。所以如果爆显你需要改的是图片的像素尺寸,而不是去压缩图片内存。
- 其次是否爆显存与显存的大小有关,与显卡处理器型号无关。所以就算是4060,显存不高也容易爆显存。
- 爆显存解决办法:
- 1:调整图片像素尺寸。
- 2:使用SD1.5 16位的大模型。
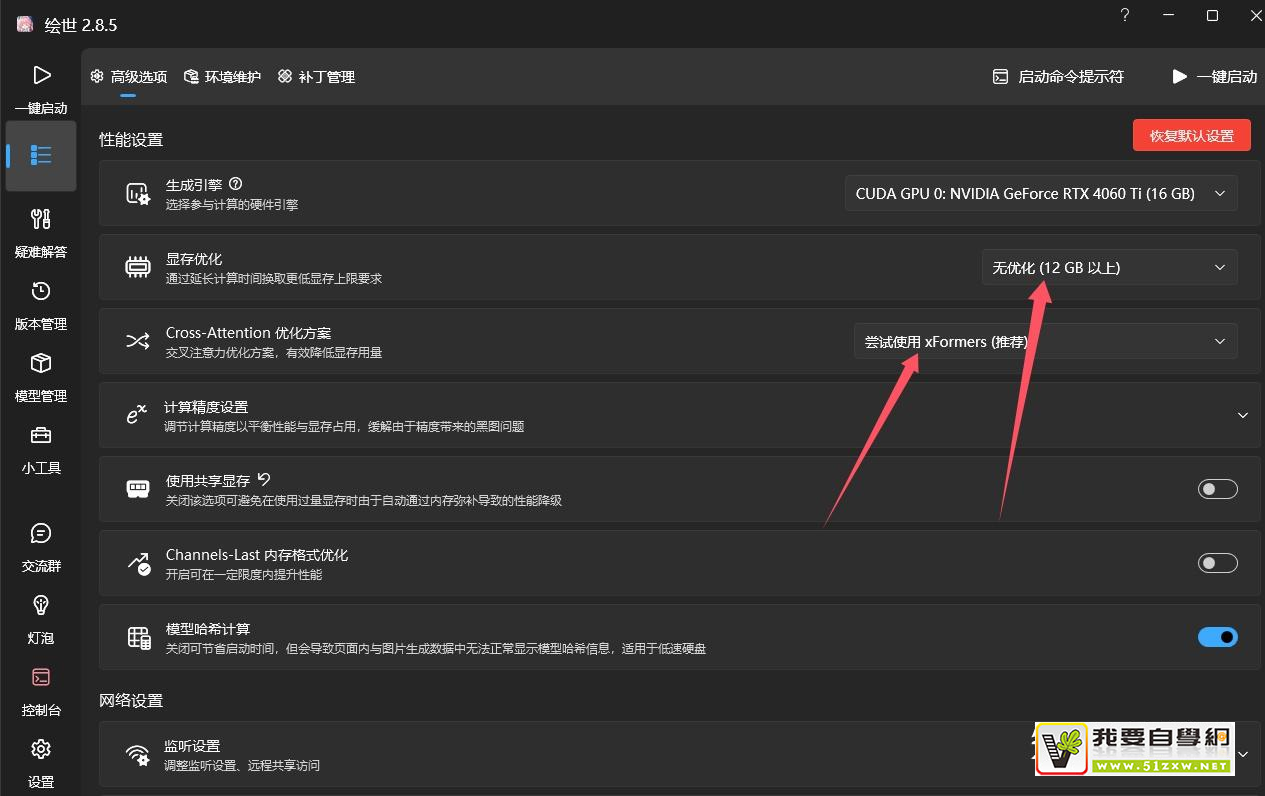
- 3:在启动器——“高级选项”——“显存优化”中更具显存大小设置对应的优化。:
- 4:在启动器——“高级选项”——“Cross-Attention 优化方案”中设置“尝试使用xFormers(推荐)
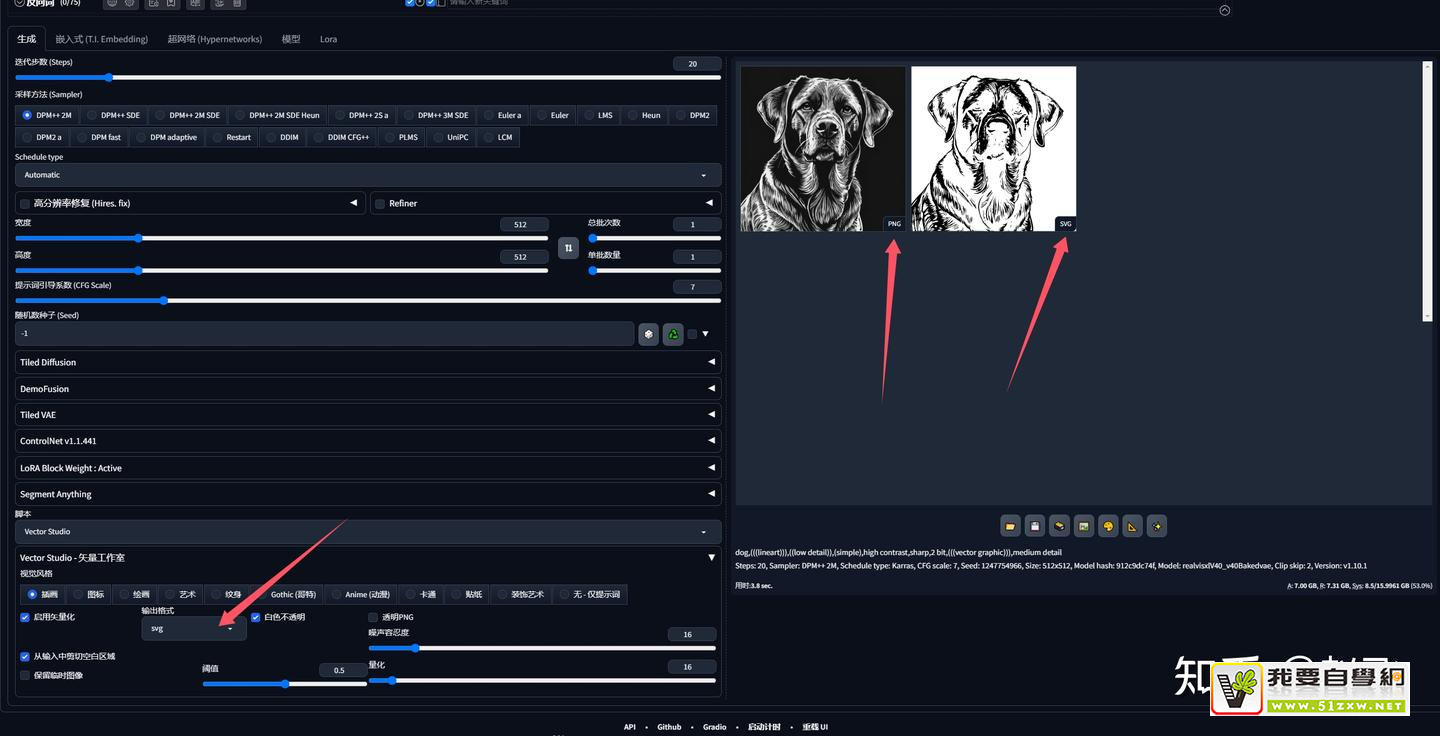
10:Stable Diffusion Vector Studio 制作LOGO无法生成vsg格式文件?
UI:Stable Diffusion WebUI
原问题:老师必须用视频中的模型和lora才能生成vsg格式文件吗??我用1.5模型导出的是是个png格式呢?
问题所在章节:6-1 Stable Diffusion设计LOGO
解决办法:
- 与大模型和LoRA无关,用什么模型都可以。
- Vector Studio - 矢量工作室输出格式设置vsg后,在生成的结果用回出现两个文件一个是PNG一个是vsg。
11:RuntimeError: tensor.device().type() == at::DeviceType::PrivateUse1 INTERNAL ASSERT FAILED at "D:\\a\\_work\\1\\s\\pytorch-directml-plugin\\torch_directml\\csrc\\dml\\DMLTensor.cpp":31, please report a bug to PyTorch. unbox expects Dml at::Tensor as inputs
UI:Stable Diffusion WebUI
原问题:老师好,用Contronet里面的任何功能都会在生成图下面出现RuntimeError: tensor.device().type() == at::DeviceType::PrivateUse1 INTERNAL ASSERT FAILED at "D:\\a\\_work\\1\\s\\pytorch-directml-plugin\\torch_directml\\csrc\\dml\\DMLTensor.cpp":31, please report a bug to PyTorch. unbox expects Dml at::Tensor as inputs 但是生成不了图片?
问题所在章节:2-30 Controlnet canny边缘检测模型讲解二
解决办法:
- 此问题是使用AMD显卡导致。使用Stable Diffusion建议使用NVIDIA显卡。
12:使用漫画助手提示词中角色与描述之间需要加逗号吗?
UI:Stable Diffusion WebUI
原问题:老师,角色girl ruoxi两个之间需要加逗号吗?
问题所在章节:6-10 Stable Diffusion 小说推文制作(一)
解决办法:
- 提示词中加不加逗号都可以
13:提示词翻译插件只有输入单个词能翻译,输入汉语句子不能翻译?
UI:Stable Diffusion WebUI
原问题:老师好,我的单个词就能翻译出来,输入句子的关键词他翻译不了,右上角会跳出'NoneType' object has noattribute 'group,请问怎么解决?
问题所在章节:2-10 提示词操作界面讲解(一)
解决办法:
- 需要在插件的API设置中将“自动翻译只使用CSV翻译(不使用网络翻译),手动点击翻译按钮才使用CSV加网络翻译。”关闭。具体操作查看2-10 提示词操作界面讲解(一)中的操作演示。
14:LayerDiffusion插件能都对图片去背景?
UI:Stable Diffusion WebUI forge
原问题:老师,请问LayerDiffusion插件可以用我上传的一张人物照片它去背景生成一张只有人物的透明图像吗?
问题所在章节:5-16 Stable diffusion webui forge版本讲解
解决办法:
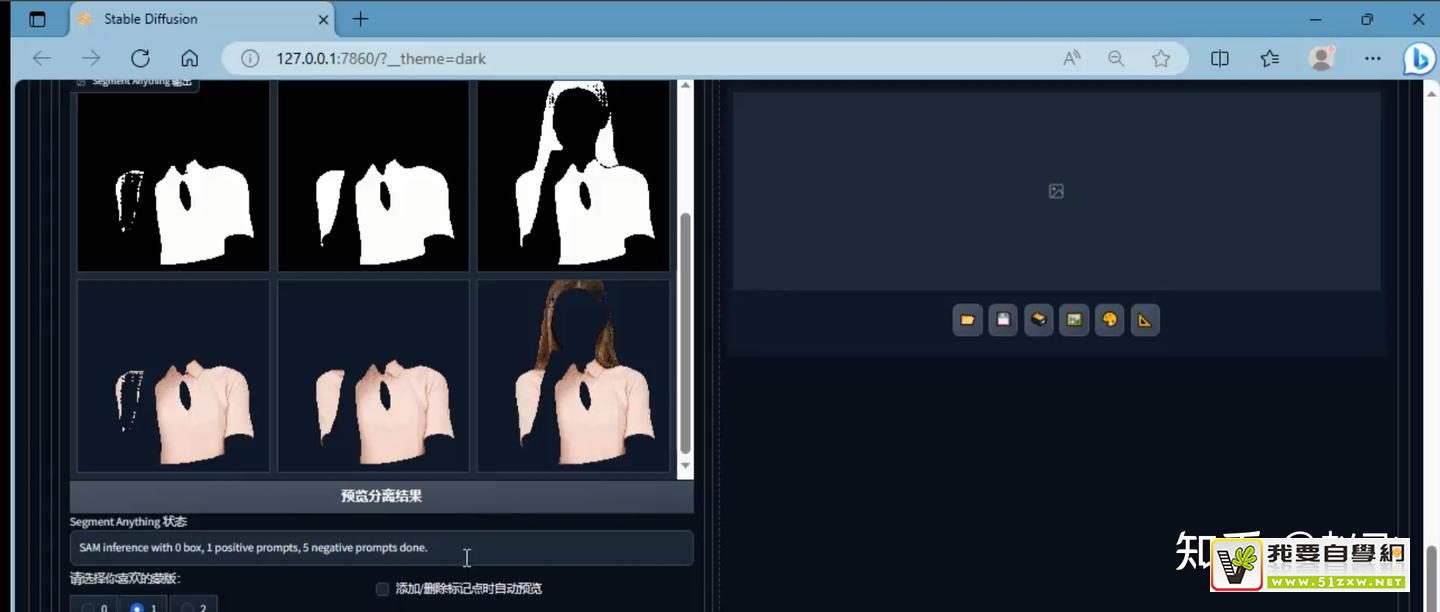
- 目前还不可以。去背景可以使用Segment anything,课程的2-49到2-52。2-49 Segment anything图像分割插件讲解(一)
15:错误提示:RuntimeError: Sizes of tensors must match except in dimension 0. Expected size 77 but got size 154 for tensor number 1 in the list.
UI:Stable Diffusion WebUI
原问题:RuntimeError: Sizes of tensors must match except in dimension 0. Expected size 77 but got size 154 for tensor number 1 in the list. 老师,这是为什么啊?提示错误了
问题所在章节:2-58 img2img alternative test图生图的替代性测试讲解
解决办法:
- 使用的 LoRA\controlnet\embedding等模型与大模型版本不匹配导致。需要确保使用的小模型与大模型版本一致。例如:大模型使用的是SDXL版本的模型,其他模型也应当使用SDXL。
16:错误提示:RuntimeError: The size of tensor a (96) must match the size of tensor b (128) at non-singleton dimension 3
UI:Stable Diffusion WebUI
原问题:RuntimeError: The size of tensor a (96) must match the size of tensor b (128) at non-singleton dimension 3 老师,我开了ControlNet,就生成不了图,显示上面的报错,怎么解决?
问题所在章节:2-38 结合Tiled diffusion放大图片
解决办法:
- 放大模型与LoRA模型版本不匹配导致。可以不使用LoRA或者更换LoRA模型解决。
17:错误提示: IndexError: string index out of rangeTime taken: 0.0 sec.
UI:Stable Diffusion WebUI
原问题:老师我按教程装上T2I-Adapter模型 运行报错 IndexError: string index out of rangeTime taken: 0.0 sec. 不能正常运行,请问要怎么处理啊
问题所在章节:2-40 Controlnet T2i-adapter与IP-adapter
解决办法:
- 更新一下Controlnet版本,如果已经是最新版本就切换到以前的版本。
18:图生图和原图完全不一样
UI:Stable Diffusion WebUI
原问题:老师的我的图生图为何很乱呢 和原图完全不一样
问题所在章节:3-2 Stable Diffusion 图生图、涂鸦讲解
解决办法:
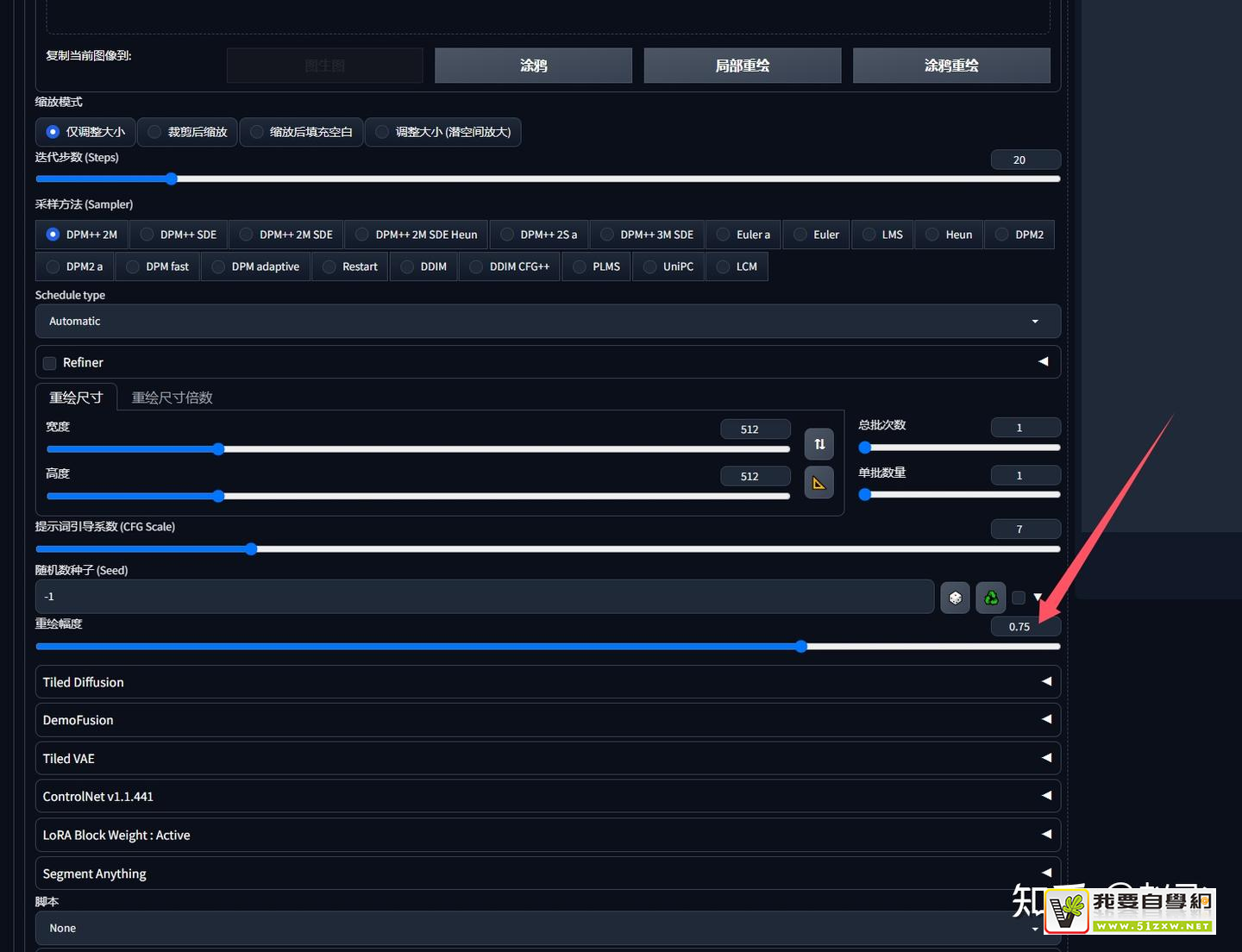
- 将重绘幅度数值调小。重绘幅度越大结果图与原图差距越大。重绘幅度越小结果图与原图差距越小。
19:错误提示:GitCommandError: Cmd('git') failed due to: exit code(128) cmdline: git fetch -v -- origin stderr: 'fatal: unable to access 'https://github.com/aigc-apps/sd-webui-EasyPhoto/': Failed to connect to github.com port 443 after 21069 ms: Couldn't connect to server'
UI:Stable Diffusion WebUI
原问题:GitCommandError: Cmd('git') failed due to: exit code(128) cmdline: git fetch -v -- origin stderr: 'fatal: unable to access 'https://github.com/aigc-apps/sd-webui-EasyPhoto/': Failed to connect to github.com port 443 after 21069 ms: Couldn't connect to server' 怎么办?
问题所在章节:6-8 一键换脸个人写真制作(二
解决办法:
- 插件无法更新导致错误。
- 1:在启动器——高级设置——监听设置中查看“开放远程链接”与“通过Gradio共享”被打开,先关闭这两个选项在更新插件,如果有需要更新完毕后再打开。
- 2:如果解决不了开启科学上网尝试。:
- 3:任然解决不了卸载EasyPhoto插件,重新安装最新版本。

20:界面区域出现两个loRA Block Weight插件是什么原因?
UI:Stable Diffusion WebUI
原问题:
| 老师,插件界面区域出现两个loRA Block Weight插件是什么原因 |
问题所在章节:2-45 Lora block weight 分块Lora权重控制插件讲解(一)
解决办法:
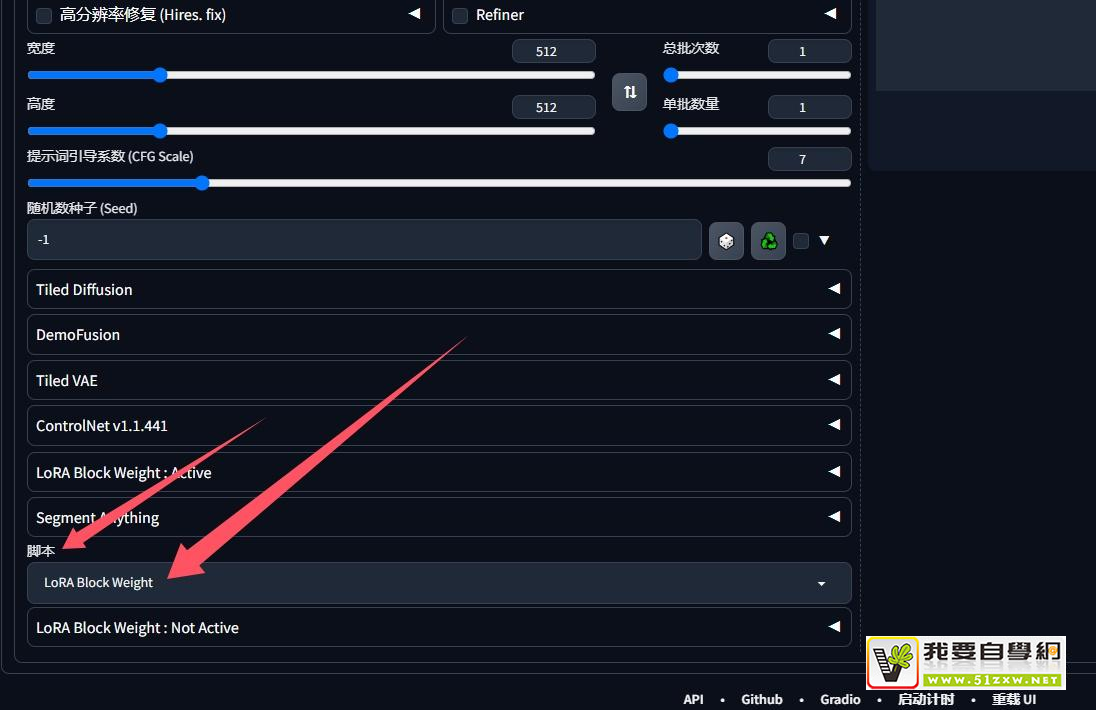
- 上面的loRA Block Weight是插件的界面。下面的loRA Block Weight是脚本的界面。这个是重复了,使用任何一个都可以。
- 想要下面的loRA Block Weight不显示,可以点击脚本的选项,选择“LoRA Block Weight”选择后再次点击脚本的选项然后选择“无”这样下面的LoRA Block Weight就不在界面中显示了。
21:错误提示:AttributeError: 'dict' object has no attribute 'shape'
UI:Stable Diffusion WebUI
原问题: 提示dict对象没有shape属性是什么意思啊?
问题所在章节:2-24 Tiled Diffusion与Tiled VAE插件讲解(三
解决办法:
- 使用哪个插件发生的错误就把那个插件更新一下,如果已经是最新的版本就切换到旧版本。注意各版本之间的对应,比如你使用的是SDXL版本的大模型,那么Controlnet模型也需要使用SDXL版本的。
22:图生图的“反推”图标按钮找不到?
UI:Stable Diffusion WebUI
原问题: 老师好!盼告下列问题的原因与解决方案。谢谢! 图生图的“反推”图标按钮找不到? 我已在启动器界面的“版本管理”中,升级内核到最新版本;另外,也检查更新了已安装的各款插件,结果还是找不到“反推
问题所在章节:3-1 CLIP反推与DeepBooru反推讲解
解决办法:
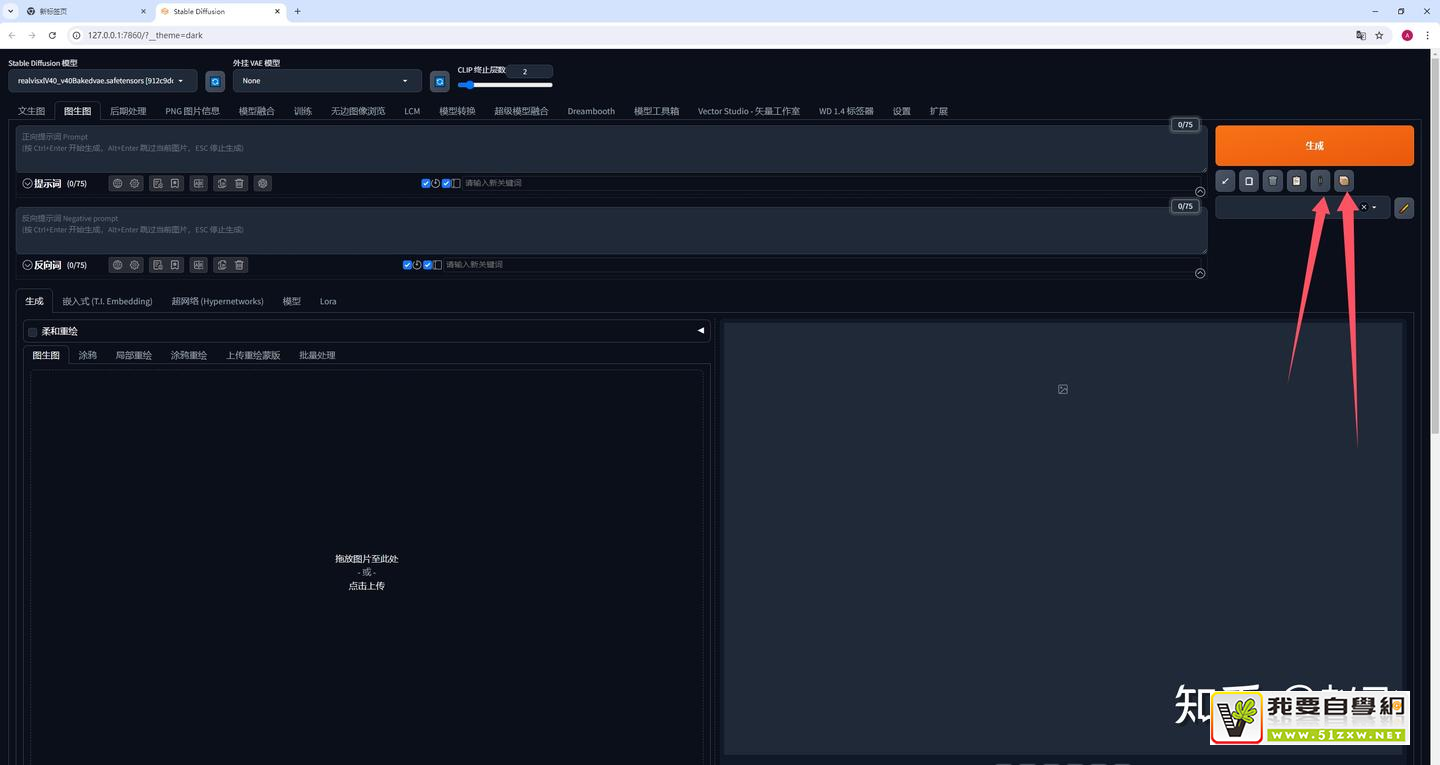
- 新版本的Stable Diffusion WebUI界面,图生图的反推按钮设计在了“生成”按钮下面的小图标位置,小图标的最后两个,一个像拉链的图标一个像正方体的图标就是之间的反推按钮。
23:错误提示safetensors_rust.SafetensorError:Errorwhiledeserializingheader:MetadataIncompleteBuffer
UI:Stable Diffusion WebUI
原问题: 老师,我刚安装完,打开只有两个界面,没有黑色那个界面弹出来。我生成图的时候,下面就出现这句提示,SafetensorError:反序列化标头时出错:MetadataIncompleteBuffer.
问题所在章节:1-7 Stable Diffusion下载与安装之整合包安装法
解决办法:
- 大模型不完整造成。检查模型是否下载的完整大模型。可以切换其他大模型尝试,或者重新下载大模型。
24:错误提示safetensors_rust.SafetensorError:Errorwhiledeserializingheader:MetadataIncompleteBuffer
UI:Stable Diffusion WebUI
原问题: error: OpenCV(4.9.0) D:\a\opencv-python\opencv-python\opencv\modules\dnn\src\layers\convolution_layer.cpp:396: error: (-2:Unspecified error) Number of input channels should be multiple of 3 but got 4 in function 'cv::dnn::ConvolutionLayerImpl::getMemoryShapes' 如何解决?
问题所在章节:4-3 自动面部焦点剪裁、Caption
解决办法:
- 版本不兼容,将内核与相关插件都更新一下。
25:错误提示:GitCommandError: Cmd('git') failed due to: exit code(128) cmdline: git clone -v --filter=blob:none -- https://github.com/ahgsql/StyleSelectorXl E:\sd-webui-aki-v4.4\tmp\StyleSelectorXl stderr: 'Cloning into 'E:\sd-webui-aki-v4.4\tmp\StyleSelectorXl'... fatal: unable to access
UI:Stable Diffusion WebUI
原问题:安装不成功 提示GitCommandError: Cmd('git') failed due to: exit code(128) cmdline: git clone -v --filter=blob:none -- github.com/ahgsql/StyleSelectorXl E:\sd-webui-aki-v4.4\tmp\StyleSelectorXl stderr: 'Cloning into 'E:\sd-webui-aki-v4.4\tmp\StyleSelectorXl'... fatal: unable to accesshttps://
问题所在章节:2-18 精炼模型refiner与SDXL大模型讲解(二)
解决办法:
- 先开启科学上网,再运行安装。
26:错误提示:使用SDXL模型与sdxl-vae时候出现黑图如何解决?
UI:Stable Diffusion WebUI
原问题:老师你好,用base和refiner的模型,vae选择sdxl-vae,跑图过程中是有图像,但是跑到100%的时候就变成黑图了。 vae换成vae-ft-mse-84000就变成花图了,请问这是什么情况呢?
问题所在章节:2-18 精炼模型refiner与SDXL大模型讲解(二)
解决办法:
- 出现黑图:打开启动器——"高级选项"——“计算精度设置”——关闭“开启VAE模型半精度优化”与“数据溢出检测”
- 花图原因:SDXL模型只能用SDXL的VAE,使用SD1.5的VAE无法正确解码,所以会花图。
27:错误提示:使用SDXL模型与sdxl-vae时候出现黑图如何解决?
UI:Stable Diffusion WebUI
原问题:RuntimeError: [enforce fail at ..\c10\core\impl\alloc_cpu.cpp:72] data. DefaultCPUAllocator: not enough memory: you tried to allocate 12582912 byte
问题所在章节:5-15 LCM模型、Turbo模型、 Lightning模型讲解
解决办法:
- 问题描述是内存不足。如果电脑内存小于16G需要升级内存配置。
- 如果内存超过16G,可以重启电脑,关闭其他占用内存的软件在尝试。
- 如果设置过虚拟内存,请将虚拟内存设置为“系统管理”
28:错误提示:AssertionError: extension access disabled because of command line flags
UI:Stable Diffusion WebUI
原问题:AssertionError: extension access disabled because of command line flags 从网址安装,URL为:GitHub - ahgsql/StyleSelectorXL: This repository contains a Automatic1111 Extension allows users to select and apply different styles to their inputs using SDXL 1.0. 报以上错误。请教老师。
问题所在章节:2-18 精炼模型refiner与SDXL大模型讲解(二)
解决办法:
- 打开启动器——“高级选项”——“监听设置”把“开放远程链接”与“通过Gradio共享”先关闭掉。然后安装插件。插件安装完成后可以再次打开。

29:错误提示:you must install.net - Domain Name For Sale | Dan.com desktop runtime to run this application
原问题:老师,安装成功了,点启动器重新英文错误,you must install.net - Domain Name For Sale | Dan.com desktop runtime to run this application,是怎么回事呀
问题所在章节:1-7 Stable Diffusion下载与安装之整合包安装法
解决办法:
- 这个错误提示表明系统中缺少必要的 .NET Desktop Runtime 组件,它是运行某些 Windows 应用程序所必需的。
- 点击此链接下载并安装.NET Desktop Runtime
- .NET Downloads (Linux, macOS, and Windows)
30:错误提示:NansException: A tensor with NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the -no-half commandline argument to fix this. Us
原问题:提示错误,打开contronlNet就这样,设置”——“SD”——“将交叉关注层向上转换到 float32”打上对勾。也还是提示一样,出不来图
问题所在章节:2-38 结合Tiled diffusion放大图片
解决办法:
- 打开启动器——“高级选项”——“计算精度设置”把“开启UNet半精度优化”与“开启VEA半精度优化”关闭。
- 还有课程讲解需要使用1.5版本的大模型。要使用SDX大模型需要用匹配版本的contronlNet模型。
31:错误提示:Allocation on device
UI:Stable Diffusion ComfyUI
原问题:SUPIR采样 Allocation on device 显示错误,老师,这是怎么回事啊
问题所在章节:4-1 ComfyUI 模糊图像变清晰
解决办法:
- 应该是现存不足造成的,把生成图片的尺寸调小,查看是否会出现此问题。
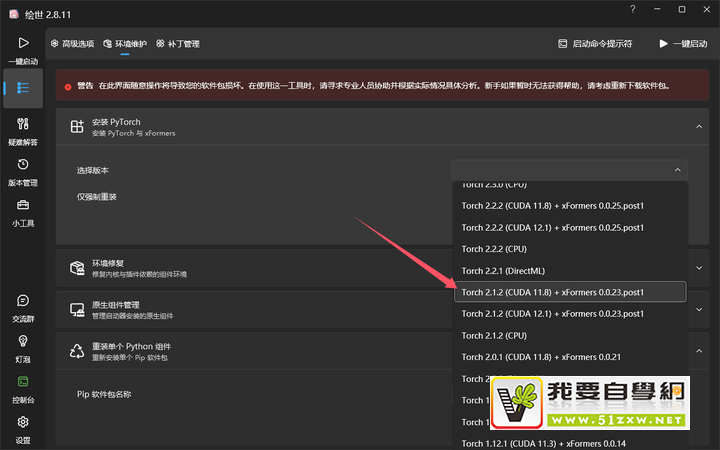
32:您当前安装的PyTorch及其附属库并不支持使用您在“生产引擎”中所选择的设备,继续运行将导致启动失败。 请前往“高级选项-环境维护”面板安装对应PyTorch版本
UI:Stable Diffusion ComfyUI
原问题:老师:启动时跳出 您当前安装的PyTorch及其附属库并不支持使用您在“生产引擎”中所选择的设备,继续运行将导致启动失败。 请前往“高级选项-环境维护”面板安装对应PyTorch版本 该怎么解决?
问题所在章节:1-3 Wndows系统安装SD ComfyUI
解决办法:
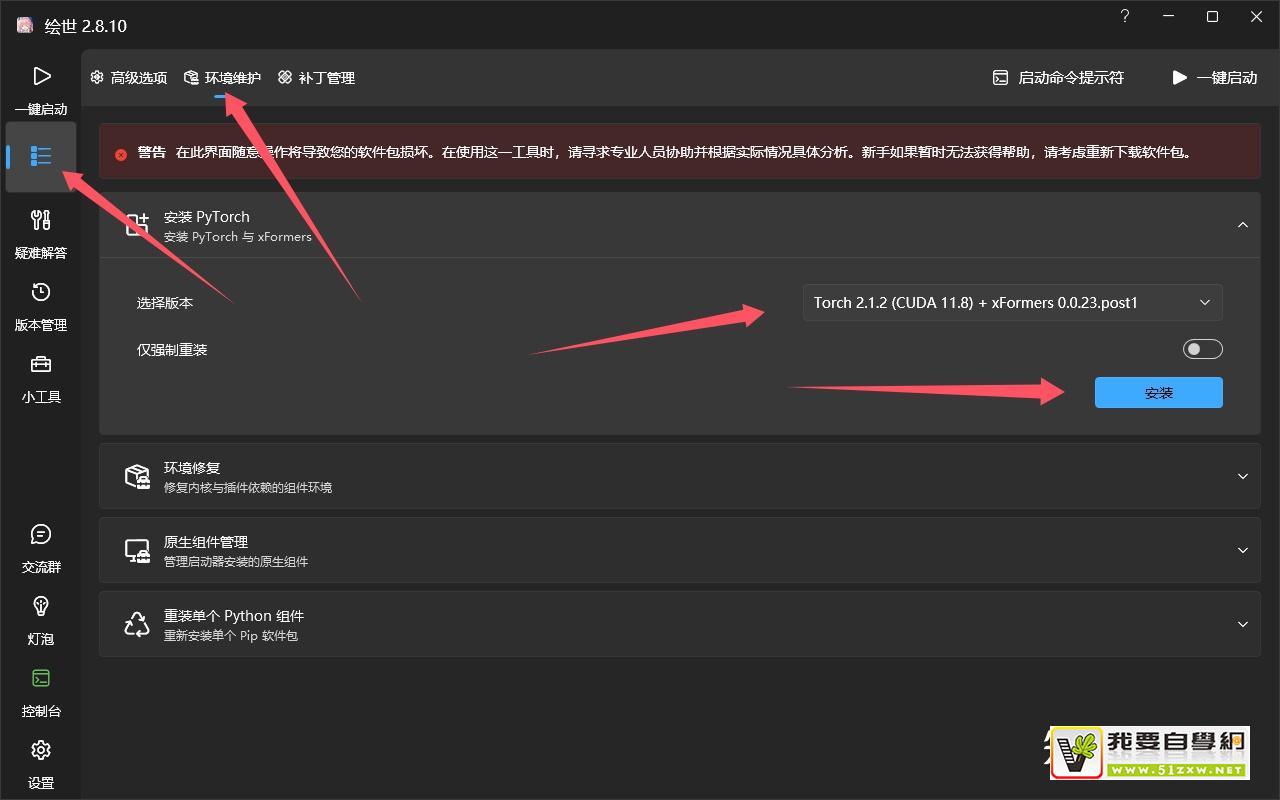
- 打开启动器——“高级选项”——“环境维护”——安装PyTorch的选择版本选择“Torch 2.1.2(CUDA 11.8)+xFormers 0.0.23.post1”点击安装。
- 若此版本不能解决问题,就提高版本安装。
33:GitCommandError: Cmd('git') failed due to: exit code(128) cmdline: git clone -v --filter=blob:none
UI:Stable Diffusion WebUI
原问题:GitCommandError: Cmd('git') failed due to: exit code(128) cmdline: git clone -v --filter=blob:none -- https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor.git E:\SD\sd-webui-aki-v4.4\tmp\stable-diffusion-webui-dataset-tag-editor stderr:
问题所在章节:5-6 Dataset Tag Editor插件讲解
解决办法:
- git进行
clone命令时出错,从克隆的网址看是需要开启科学上网的。应该是网络限制造成的问题。可以先开启科学上网再运行。
34:NansException: A tensor with all NaNs was produced in Unet. Use --disable-nan-check commandline argument to disable this check.
UI:Stable Diffusion WebUI
原问题:老师: 提示NansException:所有 NaN 的张量是在 Unet 中生成的。使用 --disable-nan-check 命令行参数禁用此检查。 有问题解决吗?已经关闭“开启UNet半精度优化”与“开启VEA半精度优化”。
问题所在章节:2-2 Stable Diffusion大模型讲解(下)
解决办法:
- 方法一:
- 1:更新webUI:打开启动器——“版本管理”——“内核”——切换版本。
- 2:更改优化方案:打开启动器——“高级选项”——“Cross-Attention优化方案”选择“自动(推荐)”
- 3:进入weiUI界面,“设置”——“SD”——将“将交叉关注层向上转换到 float32”前面的对钩打上
如果方法一操作后任然有问题,进行方法二操作。
- 方法二:
- 1:在安装根目录下找到“webui-user.bat”文件,用记事本打开此文件。将“set COMMANDLINE_ARGS=”改为:“set COMMANDLINE_ARGS=--disable-nan-check”保存文件。
35:ApplyFooocusInpaint._input_block_patch() takes 3 positional arguments but 4 were given
UI:Stable Diffusion ComfyUI
原问题:老师,我用你提供的工作流直接生成图片,显示K采样器 ApplyFooocusInpaint._input_block_patch() takes 3 positional arguments but 4 were given,是怎么回事呢
问题所在章节:2-16 局部重绘与扩图工作流创建(四)
解决办法:
- 打开启动器“版本管理”——“扩展”找到“FreeU_Advanced”扩展,把它更新到最新尝试一下。如果更新不可以就直接卸载掉。

36:NoneType' object has no attribute 'shape
UI:Stable Diffusion ComfyUI
原问题:K采样器 'NoneType' object has no attribute 'shape' 提示错误。老师,这个问题怎么解决?
问题所在章节:3-6 InstantID 与 IPAdapter 结合换脸介绍
解决办法:
- 模型版本不一致造成。比如:你的大模型使用SDXL版本,controlnet使用SD1.5版本。需要保证模型版本一致。
37:AttributeError: 'ControlNet' object has no attribute 'device'
相近问题1:Error occurred when executing KSampler: 'ControlNet' object has no attribute 'preprocess_image'
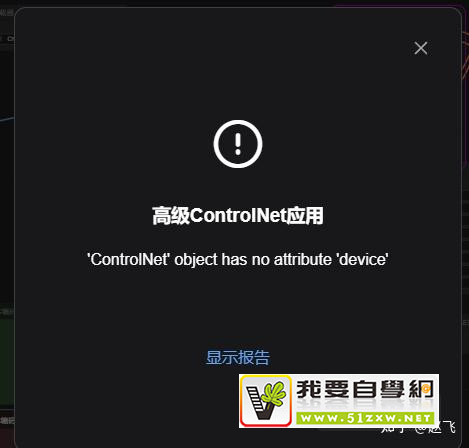
UI:Stable Diffusion ComfyUI
原问题:采样器一直报错!老师?怎么回事?Error occurred when executing KSampler: 'ControlNet' object has no attribute 'preprocess_image'
问题所在章节:2-23 Controlnet 工作流创建
解决办法:
需要更新ComfyUI-Advanced-ControlNet插件
打开启动器——“版本管理”——“扩展”找到ComfyUI-Advanced-ControlNet并更新
确保模型版本的匹配,比如大模型用SDXL模型,ControlNet模型也需要用SDXL版本
37:ValueError: operands could not be broadcast together with shapes (1424,1024,3) (1426,1024,3)

UI:Stable Diffusion ComfyUI
原问题:同上
问题所在章节:4-14 ComfyUI 电商产品修图
解决办法:
传入节点LayerUtility: HLFrequencyDetailRestore的两个图像的尺寸不一致导致。确保“image”与“detail_image”传入的图像尺寸一致。
38:error: OpenCV(4.9.0) D:\a\opencv-python\opencv-python\opencv\modules\dnn\src\layers\convolution_layer.cpp:396: error: (-2:Unspecified error) Number of input channels should be multiple of 3 but got 4 in function 'cv::dnn::ConvolutionLayerImpl::getMemoryShapes'
UI:Stable Diffusion WebUI
原问题:老师,请教一下,使用自动面部焦点剪裁功能出现以下错误,应当如何解决?error: OpenCV(4.9.0) D:\a\opencv-python\opencv-python\opencv\modules\dnn\src\layers\convolution_layer.cpp:396: error: (-2:Unspecified error) Number of input channels should be multiple of 3 but got 4 in function 'cv::dnn::ConvolutionLayerImpl::getMemoryShapes'
问题所在章节:4-2 GFPGAN、CodeFormer面部修复讲解
解决办法:
- 处理的图片中存在透明背景的图片,不要使用有透明背景的图片。
39:RuntimeError: Input type (float) and bias type (c10::Half) should be the same
UI:Stable Diffusion WebUI
原问题:同上
问题所在章节:2-23 Tiled Diffusion与Tiled VAE插件讲解(二)
解决办法:
- 打开启动器——“高级选项”——“计算精度设置”把“开启UNet半精度优化”与“开启VEA半精度优化”关闭。
40:Error occurred when executing ADE_AnimateDiffLoaderGen1: 'ModelPatcher' object has no attribute 'model_keys'
UI:Stable Diffusion ComfyUI
原问题:同上
问题所在章节:3-1 AnimateDiff Evolved动画生成插件介绍
解决办法:
- 把AnimateDiff-Evolved插件更新到最新就可以
41:AttributeError: 'NoneType' object has no attribute 'mode'
UI:Stable Diffusion WebUI
原问题:同上
问题所在章节:2-52 Segment anything图像分割插件讲解(四
解决办法:
- 在图生图生成预览才能使 Sam 有效。不要在文生图操作再切换到图生图,否则会提示错误。
42:[程序崩溃,退出代码为 3221225477 (0xC0000005)] 以下是对退出代码的分析。这可能不准确,请酌情参考! 系统退出代码名称: ACCESS_VIOLATION 系统退出代码描述: 0x%p 指令引用了 0x%p 内存。该内存不能为 %s。
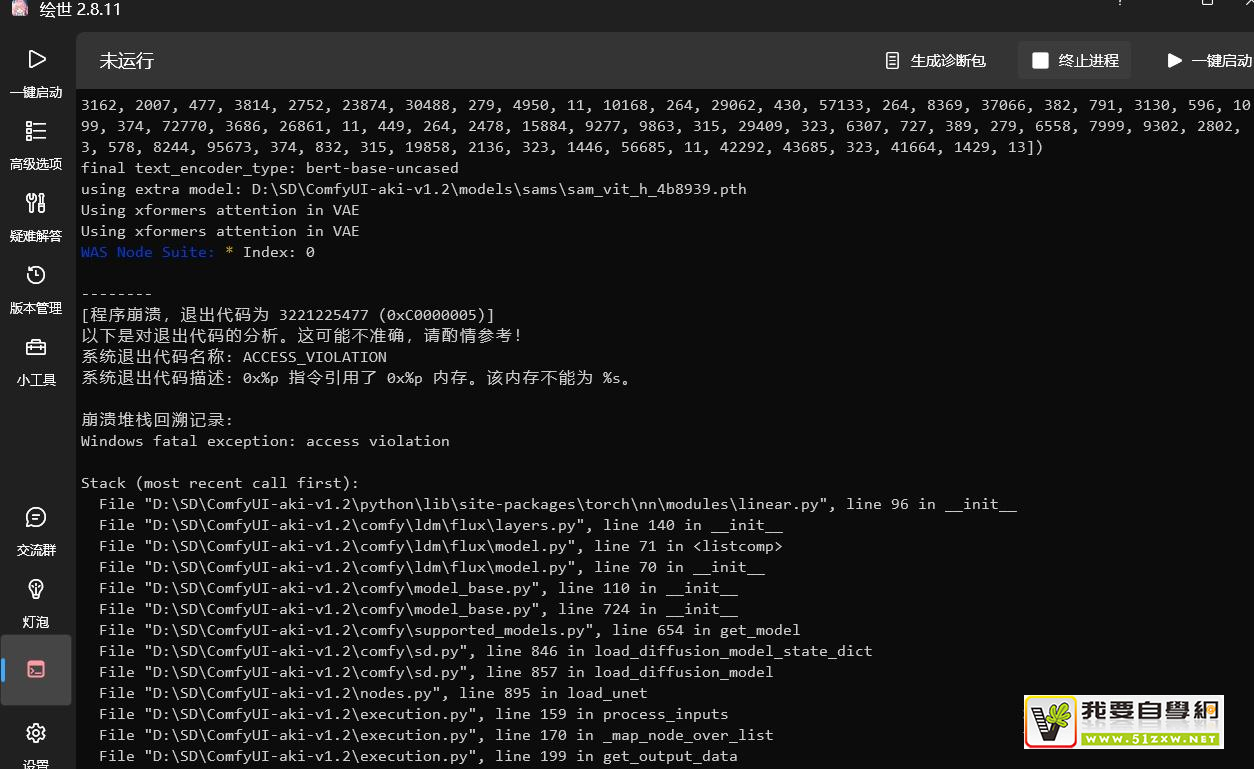
UI:Stable Diffusion ComfyUI
原问题:同上
问题所在章节:4-13 ComfyUI 海报设计(二)
解决办法:
- 内存不足引起的,换其他消耗内存小的工作流应该不会提示错误。
- 可以关闭电脑上其他占用内存的程序再运行。
- 或者升级电脑硬件,把内存提高。
43:AttributeError: 'UNetModel' object has no attribute 'default_image_only_indicator'
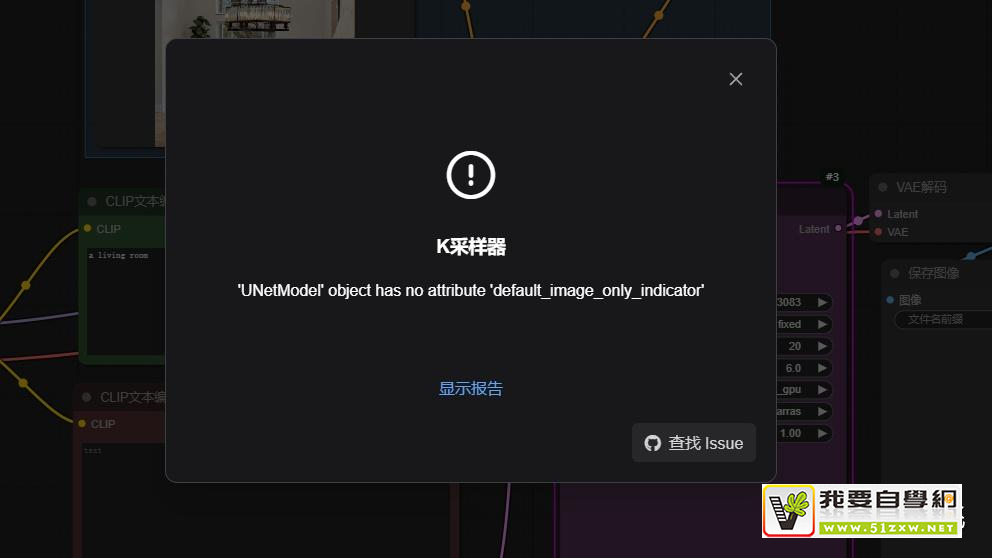
UI:Stable Diffusion ComfyUI
原问题:同上
问题所在章节:4-14 ComfyUI 电商产品修图(一)
解决办法:
- 打开启动器——“版本管理”——“扩展”找到“FreeU_Advanced”扩展,将其卸载。
44:Error(s) in loading state_dict for CLIPVisionModelProjection:size mismatch for vision_model.embeddings.patch_embedding.weight: copying a param with shape torch.Size([1152, 3, 14, 14]) from checkpoint, the shape in current model is torch.Size([1024, 3, 14, 14]).

UI:Stable Diffusion ComfyUI
原问题:同上
问题所在章节:
解决办法:
- 把comfyUI更新到最新就可以.
45:When loading the graph, the following node types were not found
UI:Stable Diffusion ComfyUI
原问题:同上
问题所在章节:2-15 局部重绘与扩图工作流创建(三)
解决办法:
- 节点缺失。点击管理器——“安装缺失节点”把列表中的节点都进行安装。
46:RuntimeError: Inplace update to inference tensor outside InferenceMode is not allowed.You can make a clone to get a normal tensor before doing inplace update.See RFC-0011-InferenceMode by ailzhang · Pull Request #17 · pytorch/rfcs for more details.
UI:Stable Diffusion WebUI
原问题:同上
问题所在章节:6-9 Stable Diffusion老照片修复
解决办法:
- 这是一个BUG,在新版本中已经修复。打开启动器——“版本管理”——“内核”把内核更新到最新就可以。
47:mat1 and mat2 shapes cannot be multiplied (256x4096 and 768x320)
UI:Stable Diffusion ComfyUI
原问题:同上
问题所在章节:2-12 图片放大工作流创建(四
解决办法:
- 大模型与LORA模型或者controlnet模型版本不匹配造成。例如大模型使用SDXL版本的模型,其他模型也需要用SDXL版本的。
48:ERROR: Could notbuild wheels for llama-cpp-python, which is required to install pyproject.toml-based projects
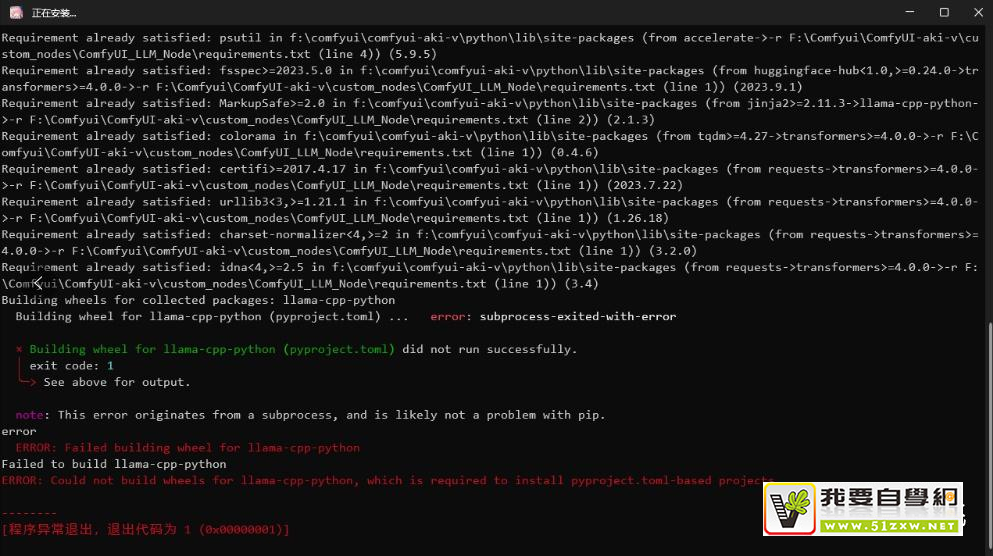
UI:Stable Diffusion ComfyUI
原问题:同上
问题所在章节:2-8 提示词进阶三(AI生成提示词)
解决办法:
- 电脑上Microsoft C++ 没有安装
- 把这个支持下载安装一下。xaiMicrosoft C++ 生成工具 - Visual Studio
47:AttributeError: 'ModuleList' object has no attribute '1'
UI:Stable Diffusion ComfyUI
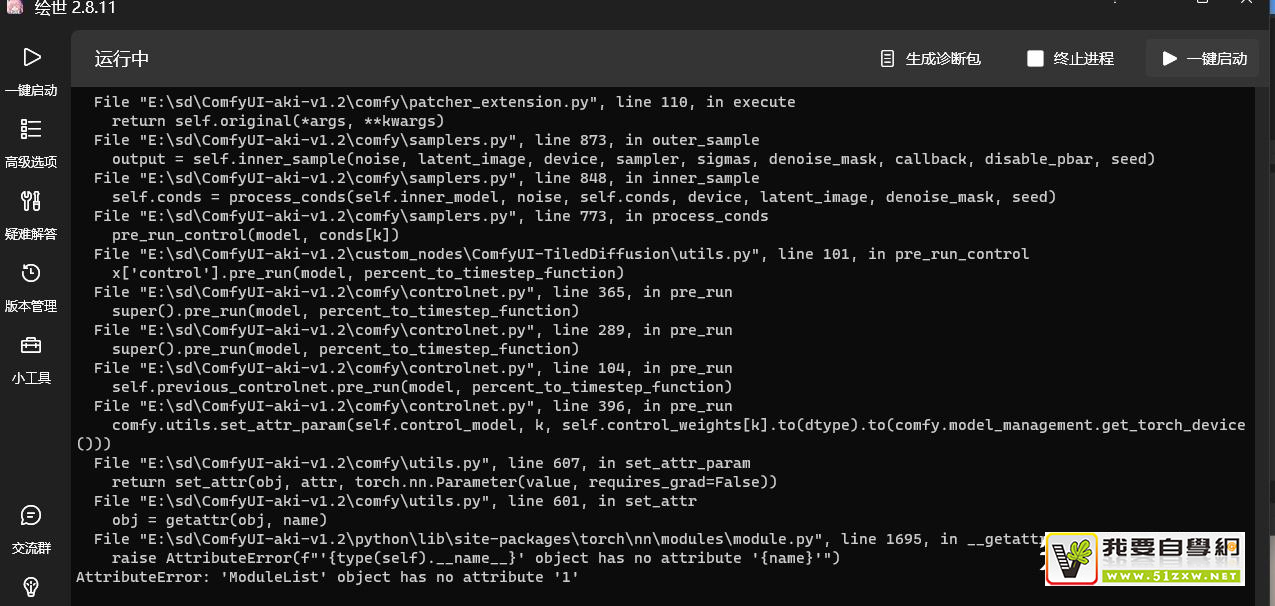
原问题:同上
问题所在章节:4-25 ComfyUI 真人转漫画与漫画转真人
解决办法:
- 大模型与LORA模型或者controlnet模型版本不匹配造成。例如大模型使用SDXL版本的模型,其他模型也需要用SDXL版本的。
48:RuntimeError: unexpected EOF, expected 2273749 more bytes. The file might be corrupted.
UI:Stable Diffusion WebUI
原问题:同上
问题所在章节:4-2 GFPGAN、CodeFormer面部修复讲解
解决办法:
- 文件损坏,需要删除以下路径的文件重新下载。
- stable-diffusion-webui\models\GFPGAN
- stable-diffusion-webui\models\Codeformer
- stable-diffusion-webui\repositories\CodeForme
- 安装后重启启动器。

59:当前分配:7.20 GIB请求:25.00 MIB设备限制:8.00 GIB免费(根据CUDA):0 BYTES PYTORCH限制(由用户提供的内存分数设置):17179869184.00 GIB
UI:稳定的扩散WebUI
原问题:同上
问题所在章节:2-52段(任何东西)
解决办法:
- 显卡显存不足造成。
- 你的(gpu (显卡)总内存为8 GIB,而当前已经分配了7.20 GIB,没有足够的空闲内存来满足额外25MIB的分配请求。
- 此外,提示中提到的,“ pytorch限制(由用户提供的内存分数设置)”指的是用户可能设置了显卡使用比例。如果你的显存大于8G稳定稳定扩散显存可使用比例。
60:HTTPSConnectionPool(host=' huggingface.co ', port=443): Max retries exceeded with url: /Kijai/LivePortrait_safetensors/resolve/main/appearance_feature_extractor.safetensors (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x0000019a026a5330>,'连接到huggingface.co时机。 ((连接超时=无)(无))
UI:稳定的扩散comfyui
原问题:同上
问题所在章节:3-5 AdvancedLivePortrait
解决办法:
- 1 、网路限制问题,先开启学科上网再运行。
- 2 、如果开启学科上网后任然是同样的错误,那可以拉去的项目已经不存在,或者被禁止。可以先通过项目网址看一下项目是否存在。,或者被禁止。可以先通过项目网址看一下项目是否存在。
61:attributeError:'nontype'对象没有属性'shape'
UI:稳定的扩散WebUI
问题所在章节:6-9稳定扩散老照片修复
解决办法:
- 模型版本不比配造成。比如你的大模型使用的是sdxl版本的模型,你的controlnet或者其他模型使用的是sd1.5版本模型。确保模型版本使用一致。
62:pydantic_core._pydantic_core.validationError:1 generateRequest模型字符串的验证错误应至少具有1个字符[type = String_too_short,input_value ='',input_type = str]以获取更多信息,请访问https :

UI:稳定的扩散comfyui
原问题:同上
问题所在章节:2-8提示词进阶三(AI生成提示词)
解决办法:
- 此问题为工作流中使用了ollama节点,节点中调用了ollama部署的本地模型。但运行工作流的时候没有开启
- 开启ollama软件后刷新工作流可以解决问题。
63:free_upper_bound + pytorch_used_bytes [device] <= device_total内部assert在“ .. \\ c10 \\ cuda \\ cudamallocasyncallocator.cpp”:540上失败。
UI:稳定的扩散comfyui
原问题:同上
问题所在章节:4-29(comfyui))
解决办法:
- 这个错误表明在使用pytorch时,cuda的异步内存分配器(cudamallocasyncallocator)出现了内部错误。这通常是由于显存不足或内存分配错误导致的。
- 先把生成图片的尺寸调小进行生成,从而判断是否是显存不足造成。效果小尺寸图能够生成


64:警告:根:采样器调度程序自动更正:“无” DPM ++无”自动
UI:稳定的扩散WebUI
问题所在章节:4-8岁(嵌入模型训练(二)
解决办法:
- 错误提示表明选择的采样器调度器参数不符合预期。应该是内核版本问题导致部分采样器与调度器发生变化导致。
- 稳定的扩散webui采样器与调度器的设置最开始是一个选项,后来的版本进行了分开,变成两个选项。
- 在启动器的“版本管理” - - “内核”进行更新。
- 如果已经是最新的版本就换一个采样器与调度器。
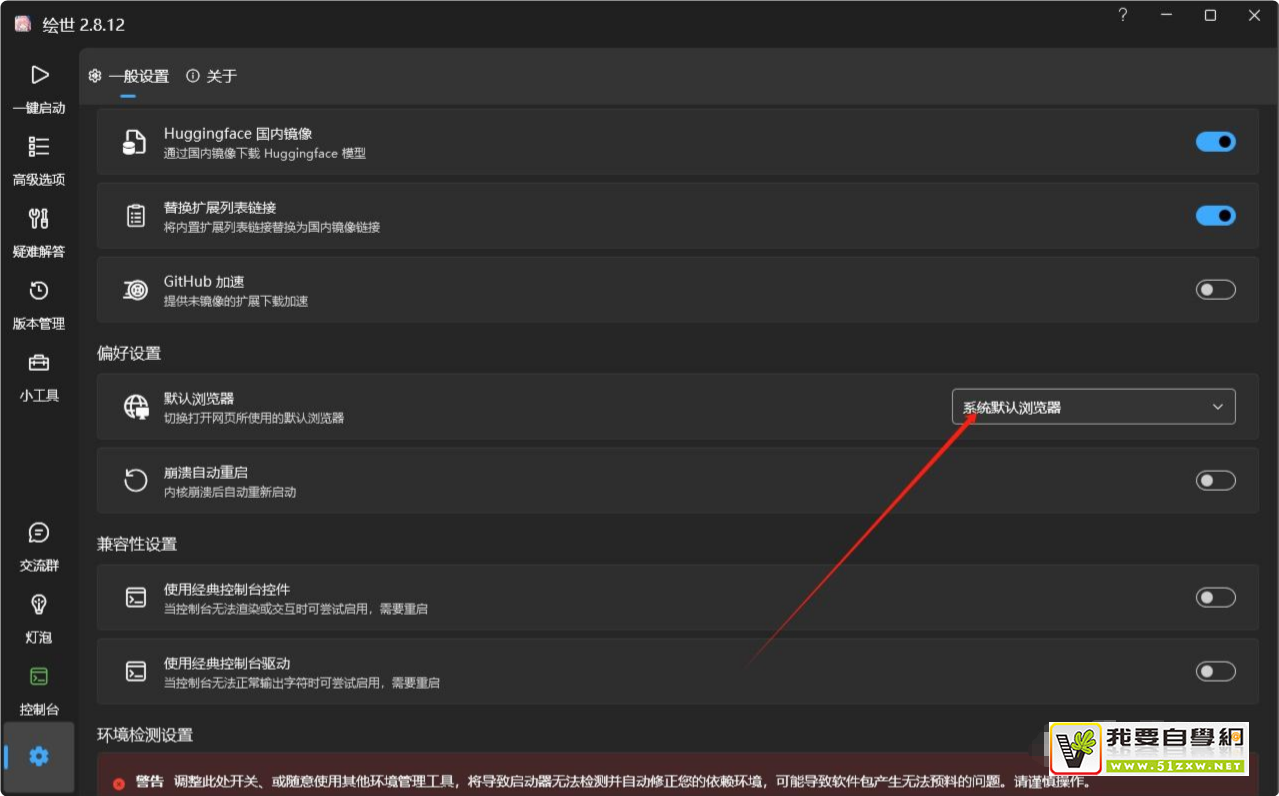
65:comfyui如何修改打开的默认浏览器。
UI:稳定的扩散comfyui
原问题:老师,因为我的电脑上装了三个浏览器,如何可以让
问题所在章节:1-6 SD comfyui基础概念与操作界面介绍
解决办法:
- comfyui在没设置的情况下,默认打开电脑系统默认的浏览器,所以修改电脑上的默认浏览器打开程序可以修改comfyui默认的打开浏览器。
- 如果要只为comfyui指定默认浏览器,可以打开启动器———“设置” - “偏好设置” - “默认浏览器”中进行设置。
66:TypeError:参数插值应为interpolationmode或相应的枕头整数常数
UI:稳定的扩散WebUI
原问题:文件“
问题所在章节:2-31 ControlNet深度深度模型讲解
解决办法:
- 首先把你安装路径中的中文文件夹改成英文再尝试运行一下。
- torchvision和枕头不兼容导致的。可以在启动器的“高级选项” - - “环境维护” - “安装pytorch”中切换版本。
- 以下是老师的环境版本可以做参考:火炬2.0.1+CU118,python 3.10.11,版本:v1.10.1、 xformers 0.0.21
67:OutofMemoryError:设备0上的分配将超过允许的内存。 ((目前分配的记忆):4.73 GIB请求:25.00 MIB设备限制:8.00 GIB免费((根据CUDA):0 BYTES PYTORCH限制(用户提供的内存分数设置(17179869184.00 GIB gib用时:34.7 sec)。
UI:稳定的扩散WebUI
问题所在章节:6-7 一建换脸个人写真
解决办法:
- 这是显存不足爆显存。
- 可以降低图片是生成尺寸,生成批次使用1。
- 下载使用的模型可以使用半精度的模型。
- 启动器的“高级选项” - - “显存优化”更具自己显存设置优化。
- 启动器的“高级选项” - “使用共享显存”打开此选项。
- 以上如果任然解决不了问题那么就需要更换更大显存的显卡。

67:断言:扩展目录已经存在:
UI:稳定的扩散WebUI
原问题:assertionError:扩展目录已经存在:d:\稳定扩散\ sd-webui-aki-v4.4 \ Extensions \ sd-webui-easyphoto?
问题所在章节:6-6电商产品换背景
解决办法:
- 插件已经存在,或者删除不完全,插件的文件夹任然存在,导致无法再次安装。,导致无法再次安装。
- 到SD根目录下的扩展文件夹,找到对应插件的文件夹手动删除就可以。,找到对应插件的文件夹手动删除就可以。
68:应用pupulidflux意外EOF,预计927144个字节。该文件可能会损坏。
UI:稳定的扩散comfyui
原问题:施加Pulid Flux运行到这个节点报错,怎么处理?施加pulidflux意外EOF,预计927144个字节。该文件可能会损坏。
问题所在章节:4-32 comfyui美妆迁移
解决办法:
- 该问题是由于位于comfyui \ python \ lib \ site-packages \ facexlib \ weights
- 删除所有三个.pth文件,然后运行然后运行工作流。它会自动加载这三个文件。
- 如果安装的不是秋叶整合包,是纯净版路径为\ python_embed \ lib \ site-packages \ facexlib \ striges









承担因您的行为而导致的法律责任,
本站有权保留或删除有争议评论。
参与本评论即表明您已经阅读并接受
上述条款。